![]()

2000-2001 Seminar, Mayo's Error Statistics [Last update: September 25, 2001]
We will continue the same book for the 2001 academic year too; in all probability we will start from Chapter 5, so that newcomers should review chh.1-4 in advance (see below). For Assignments, see the bottom of chapters. For the Newcomers
We will read and discuss the following book, which is quite influencial in recent philosophy of science:
Deborah. G. Mayo, Error and the Growth of Experimental Knowledge, University of Chicago Press, 1996. [For the author and the book, see the following sites: http://www.phil.vt.edu/people/faculty.htm; http://borg.lib.vt.edu/vtpubs/spectrum/sp981210/5d.html]
According to the author, the basic feature of her theory is summarized as follows:
I have attempted to set out the main ingredients for a non-Bayesian philosophy of science that may be called the error-statistical account. The account utilizes and builds upon several methods and models from classical and Neyman-Pearson statistics, but in ways that depart from what is typically associated with these approaches enough to warrant some new label. Because the chief feature that my approach retains from Neyman-Pearson methods is the centrality of error probabilities, the label "error statistics" seems about right. Moreover, what fundamentally distinguishes this approach from others is that in order to determine what inferences are licensed by data it is necessary to take into account the error probabilities of the experimental procedure. In referring to an error-statistical philosophy of science, I have in mind the various ways in which statistical methods based on error probabilities may be used in philosophy of science. At present, when it comes to appealing to statistical ideas in philosophy of scientific inference, the Bayesian Way is sometimes thought to be the only game in town. What I wish to impress upon the reader is that an error-statistical philosophy of science presents a viable alternative to the Bayesian Way. (442)
In the error theorist's approach, experimental inquiry is viewed in terms of a series of models: primary models, experimental models, and data models. In an experimental inference, primary hypotheses are linked to models of data by means of experimental tests, and hypotheses are inferred according to whether they pass severe tests. Methodological rules are regarded as claims about strategies for coping with, and learning from, errors in furthering the overarching goal of severe testing, and rules are assessed according to their role in promoting that end. (443)
Instructions and notices are going to be shown in this web page; do not neglect to visit this site occasionally!
Important passages from each chapter:
Chapter 1. Learning from Error
Mayo's central idea is stated:
The centerpiece of my argument is the notion of severity involved. Unlike accounts that begin with evidence e and hypothesis H and then seek to define an evidential relationship between them, severity refers to a method or procedure of testing, and cannot be assessed without considering how the data were generated, modeled, and analyzed to obtain relevant evidence in the first place. I propose to capture this by saying that assessing severity always refers to a framework of experimental inquiry. (11)
... I want to claim for my own account that through severely testing hypotheses we can learn about the (actual or hypothetical) future performance of experimental processes---that is, about outcomes that would occur with specified probability if certain experiments were carried out. This is experimental knowledge. In using this special phrase, I mean to identify knowledge of experimental effects (that which would be reliably produced by carrying out an appropriate experiment)---whether or not they are part of any scientific theory. ... To paraphrase Ian Hacking, it may be seen as a home in which experiment "lives a life of its own" apart from high-level theorizing. (11-12)
Notice that Mayo's notion of the "reliability of a hypothesis" is quite different from the Bayesian notion.
Lerarning that hypothesis H is reliable, I propose, means learning that what H says about certain experimental results will often be close to the results actually produced---that H will or would ofen succeed in specified experimental applications. ... This knowledge, I argue, results from procedures (e.g., severe tests) whose reliability is of precisely the same variety. (10, Uchii's italics)
Mayo's list of canonical types of error; she argues that we learn from errors by a piecemeal method, by methodological rules for avoiding these types of error.
a. mistaking experimental artifacts for real effects; mistaking chance effects for genuine correlations or regularities;
b. mistakes about a quantity or value of a parameter;
c. mistakes about a causal factor;
d. mistakes about the assumptions of experimental data. (18)
Chapter 2. Ducks, Rabbits, and Normal Science
Mayo compares Popper's and Kuhn's view of science, and reinterprets and supports Kuhn's view, as follows:
Normal scientists, in my rereading of Kuhn, have special requirements without which they could not learn from standard tests. They insist on stringent tests, reliable or severe. They could not learn from failed solutions to normal problems if they could always change the question, make alterations, and so on. (54)
But she denies the distinction between normal science and revolutionary science:
My solution is based on one thing normal practioners, even from rival paradigms, have in common (by dint of enjoying a normal testing tradition): they can and do perform the tasks of normal science reliably. That is the thrust of Kuhn's demarcation criterion. (54-55)
... I do not accept Kuhn's supposition that there are two kinds of empirical scientific activities, normal and revolutionary: there is just normal science, understood as standard testing. (55)
See Popper vs. Kuhn, reconstrued by Mayo
1st Assignment: āüāCāłü[é╔éµéĻé╬üAāNü[āōé╠üuÆ╩ÅĒē╚ŖwüvéŲüuŖļŗ@é╠ē╚Ŗwīżŗåüvé╠ŗµĢ╩é═éŪé╠éµéżé╔ēÄ▀é│éĻüAéŪé╠éµéżé╔ößö╗é│éĻéĮé®üB2000ÄÜł╚ōÓüAÆ„é▀ÉžéĶ11īÄ21ō·
Chapter 3. The New Experimentalism and the Bayesian Way
Mayo calls those people who regard experimental inquiry in science as vital, "New Experimentalists"; these include Robert Ackermann, Nancy Cartwright, Allan Franklin, Peter Galison, Ronald Giere, and Ian Hacking. Their views present a new stance against the post-Kuhnian, theory-dominated stances. And Mayo tries to clarify the epiostemology of this stance, along the line presented in chapter 1, learning from error.
Experimental activities do offer especially powerful grounds for arriving at data and distinguishing real effects from artifacts, but what are these grounds and why are they so powerful? ...
As a first step we can ask, What is the structure of the argument for arriving at this knowledge? My answer is the one sketched in chapter 1: it follows the pattern of an argument from error or learning from error. The overarching structure of the argument is guided by the following thesis:
It is learned that an error is absent when (and only to the extent that) a procedure of inquiry (which may include several tests) having a high probability of detecting the error if (and only if) it exists nevertheless fails to do so, but instead produces results that accord well with the absence of the error.
Such a procedure of inquiry is highly capable of severely probing for errors---let us call it a reliable (or highly severe) error probe. According to the above thesis, we can argue that an error is absent if it fails to be detected by a highly reliable error probe. (64)
As Mayo said in the Preface, she regards this approach as a viable alternative to the Bayesian Way, which uses Bayesian inference as the key for understanding scientific inferences. She distinguishes three main ways (p. 70) in which a mathematical theory of probability can be used in philosophy of science:
1. A way to model scientific inference
2. A way to solve problems in philosophy of science
3. A way to perform a metamethodological critique
The rest of chapter 3 is devoted to criticisms of the Bayesian Way. Although her discussion of the Baysian Way continues in later chapters, I (being a Bayesian myself) have to raise a basic question here. Are her criticisms, all in all, fair? Has she really succeeded in avoiding the use of the Bayesian notion of probability in her arguments?
You may recall that the frequentist had a grave difficulty as regards the probabilities of "single events" and of "hypotheses" or "propositions". Offhand, I suspect that her transition from "error probability" to "reliability" smuggles in a non-frequentist or Bayesian probability. The point is: distinguish (1) a reference to the known relative frequency of something, and (2) the use of that value as a measure of reliability in some practical context; (1) does not automatically warrant (2), which gives a practical guidance. But more on this later.
See Neyman-Pearson, Fisher, Bayes revised May 7, 2001; Wes Salmon on the Probability of Single Events revised May 1, 2001
Mayo, after her criticism of subjectivity of the Bayesian Way, refers to "washout theorems" (84) and argues as follows:
The real problem is not that convergence results hold only for very special circumstances; even where they hold they are beside the point. The possibility of eventual convergence of belief is irrelevant to the day-to-day problem of evaluating the evidential bearing of data in science. (84)
But if she argues this way, exactly the same criticism applies to the frequentist (I presume she is one), when he/she wants to use the value of probability (that is, the limit of relative frequency) as a measure of "reliability" or "severity" (or whatever) of tests, because, such a measure has to be conferred, eventually, on single cases with which the day-to-day problems are primarily concerned. As I have pointed out in my criticism of Wes Salmon (who is a conscientious frequentist), the frequentist has to rely on the possibility of convergence (not of opinion, but of relative frequency), even for applying probability to single cases! And worse, the frequentist completely fails to explain the prescriptive or pragmatic import of probability, which is crucial for its application to single events. So far, I have been unable to find any passage in which Mayo discusses the probability of single events, or applications of error probability to single cases; thus I feel Mayo is not as conscientious as Wes Salmon.
Chapter 4. Duhem, Kuhn, and Bayes
This chapter continues criticisms of the Bayesian Way, and presents Mayo's alternative account of the way out of the the Duhem problem. The Duhem problem is, Which of a group of hypotheses used to derive a prediction should be rejected when experiment disagrees with that prediction?
When Bayesians say they can solve Duhem's problem, what they mean is this: Give me a case in which an anomaly is taken to refute a hypothesis H out of group of hypotheses used to derive the prediction, and I'll show you how certain prior probability assignments can justify doing so. The "justification" is that H gets a low (or lower) posterior probability than the other hypotheses. (103)
Mayo does not like this. Reconstructing a refutation of a hypothesis in terms of the Bayesian Way does not solve the prblem, Mayo argues. Instead, Mayo follows Giere's line, a "technological fix for the Duhem-Quine problem".
My position for solving Duhem extends this technological fix to include any experimental tool. It is the reliability of experimental knowledge in general, the repertoire of errors and strategies for getting around them, that allows checking auxiliaries, and for doing so quite apart from the primary subject matter of experiments. (110)
In the remainder of this chapter, Mayo examines Wes Salmon's attempt at the problem in his paper on "Tom Kuhn meets Tom Bayes" (1990). This is quite interesting, but it illuminates the difficulties of the frequentist's rendering of prior probabilities. Mayo suggests that the Error Statistics can provide a better means. However, my suspicion continues.
Added Feb. 9, 2001.
One thing you have to remember is that Mayo defines the "Bayesian catchall factor" in this chapter (116), and this plays some important role in her later argument against Bayesians. If you want to assess T (theory or hypothesis) with evidence e, the Bayesian catchall factor is
P(e, not-T).
T itself has a definite content; but not-T is "the disjunction of all possible hypotheses other than T, including those not even thought of, that might predict or be relevant to e." Mayo sees here a grave, or a fatal, difficulty for Bayesians; for such a probability may well be meaningless, but Bayesians need it. Maybe we can discuss this problem later.
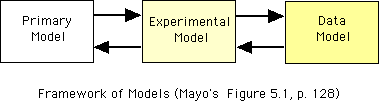
Chapter 5. Models of Experimental Inquiry
In this chapter, Mayo, drawing on Patrick Suppes's idea, develops the framework for treating theories, experiments, and data. This is generally in accord with the so-called "semantic view of theories".
See the following figure and explanation:
Primary models: How to break down a substantive inquiry into one or more local questions that can be probed reliably.
Experimental models: How to relate primary questions to (canonical) questions about the particular type of experiment at hand.
Data models: How to generate and model raw data so as to put them in canonical form. How to check if the actual data generation satisfies various assumptions of experimental models. (Table 5.1, 130)
For an example, see this figure revised, Apr. 24; Binomial Experiment Revised, Apr. 3; Basics of Statistics Revised, May 1; The Chi-Square Test New, May 7; The Law of Large Numbers, May 8
Added April 20, 2001: To make Mayo's long story short!
Mayo's arrangement of materials is not well-organized, to say the least. The reader is demanded to understand the role of experimental model and others, with a sketchy description of the British expedition of 1919 for testing a prediction from general relativity (a more detailed description comes only in Ch. 8; see Eddington on 1919 Expeditions). If I may give my candid opinion, what she should do in this Ch. 5 is to familiarize the reader with the role of experimental models, in terms of a simple and straightforward example. She says, an experimental model has two functions: (1) the primary question is related to a particular experiment (or observation) by means of this model, and (2) the data obtainable from such an experiment are related to experimental questions.
In the barest essentials, Einstein's general relativity predicts the deflection of starlight by the sun (the angle of deflection is specified); so the primary question is "Is that true?" Then the next question is, how can we answer that question? Naturally, we've got to make some observation or experiment; but how? We've got to relate the primary question to what may be expected from such and such experiments; thus we need an experimental model which can fill in this detail. But what can be "observed" during the eclipse of 1919, at Sobral or Principe? Take photos, the sun with several stars around it, and compare them to other similar photos taken when the sun is away! So the experimental model begins to emerge. But still, it's a long way from such photos to the primary question; the raw data (photos) are not useful unless their contents are extracted (inferred) in some form amenable to the primary question. Supposing those photos are the "raw data", we need experimental hypotheses which specify these contents from the raw data; thus the experimental question is whether or not these hypotheses are true. And the raw data themselves must be transformed, so to speak, to match such hypotheses. In our case, the displacements of the image of each star (on the photos) are now picked out as data; and from this, the angle of deflection can be calculated. Thus, not raw data themselves, but a data model is needed in this way. Further, since observations and experiments are not infallible, the question becomes that of probability; how are they reliable, what is the probability of error? Thus, aside from other technical treatments of raw data, error statistics is called for.
1st Assignment, 2001
æµ1ē±ē█æĶ ü@æµ5Å═üi5.4é▄é┼üjé╠ŚvÄ|üBÄ└ī▒ōIÆTŗüé╠āéāfāŗé╠ŖKæwéŲé╗éĻéńé╠¢ŖäéüAŗ’æ╠Śßé╔æ”éĄé─é┼é½éķéŠé»éĒé®éĶéŌéĘéŁüA2000ÄÜł╚ōÓé┼é▄éŲé▀éµüB
Æ„é▀ÉžéĶ5īÄ18ō·üiŗÓüj
Chapter 6. Severe Tests and Methodological Underdetermination
Mayo has kept us waiting for seeing her specific account of the severity of a test; now she begins that. The basic question to which she wants to address herself is the question of methodological underdetermination (MUD) :
any evidence taken as a good test of (or good support for) hypothesis H would (on that account of testing or support) be taken as an equally good test of (or equally good support for) some rival to H. (176)
This is the thesis of methodological underdetermination, and Mayo's question is, how should we avoid this? She tries to resolve this difficulty by appealing to the notion of severity of test.
Stated simply, a passing result is a severe test of hypothesis H just to the extent that it is very improbable for such a passing result to occur, were H false. Were H false, then the probability is high that a more discordant result would have occurred. To calculate this probability requires considering the probability a given procedure has for detecting a given type of error. This provides the basis for distinguishing the well-testedness of two hypotheses---despite their both fitting the date equally well. (178)
In a word, given a number of hypotheses and a piece of evidence (obtained by a test), we can single out the best tested theory according to the degree of the severity of the test, thus enabling us to avoid the difficulty of underdetermination.
Mayo proposes several versions for severity criterion (SC), but we will reproduce only one, called (1a). Stipulation is that, a hypothesis H is tested according to procedure T and the test result is e:
There is a high probability that test procedure T would not yield such a passing result, if H is false. (180)
The severity ranges from 0 (minimum) to 100 percent (maximum); that is, H passes a 0-severity test with e if T would always yield such a passing result even if H is false, and H passes a 100-severity test with e if T would never yield such a result if H is false. Normally, the severity value comes somewhere in between, depending on the probability in question.
With this criterion in hand, Mayo deals with the Alternative Hypothesis Objection (which is meant to support MUD): "the fact that the data fit hypothesis H fails to count in favor of H because the data also fit other, possibly infinitely many, rival hypotheses to H." (187) Here, Mayo's arsenal of the hierarchy of models begins to be useful.
To be specific, consider the famous experiment (observation) of 1919 for the general theory of relativity (GTR): British physicists tried to ascertain the deflection of light around the sun, during the solar eclipse in that year. Mayo argues, that Earman's construal of that experiment in terms of the obtained data, the GTR, and its negation (all other hypotheses included) are misguided. Mayo's diagnosis is illuminating:
But alternatives to the GTR did not prevent the eclipse results from being used to test severely the hypotheses for which the eclipse experiments were designed. Those tests, ..., proceeded by asking specific questions: Is there a deflection of light of about the amount expected under Einstein's law of gravitation? Are alternative factors responsible for appreciable amounts of the deflection? Finding the answers to these questions in a reliable manner did not call for ruling out any and all alternatives to the general theory of relativity. (188)
Take the question of deflection. Given this question (primary question), alternative answers to it are alternative values of deflection, not alternatives to the GTR, Mayo points out. Thus the probability needed for calculating the severity of this test has no need to appeal to alternative thoeries to the GTR; and the severity can be judged within this local context. This is a very good point, and many people have missed it. But once made clear, it can help Bayesians as well as error statisticians, contrary to Mayo's allegation! Let's listen to Mayo's argument.
For a result to teach something about the theory, say the GTR, for a Bayesian, that theory must have received some confirmation or support from that result. But that means the theory, the GTR, must figure in the Bayesian computation. That, in turn, requires considering the probability of the result on the negation of the GTR, that is, the Bayesian catchall factor. That is why Earman's criticism raises a problem for Bayesians.
For the error theorist, in contrast, an experiment or set of experiments may culminate in accepting some hypothesis, say about the existence of some deflection of light. This can happen, we said, if the hypothesis passes a sufficiently severe test. That done, we are correct in saying that we have learned about one facet or one hypothesis of some more global theory such as the GTR. Such learning does not require us to have tested the theory as a whole. (190)
Mayo's criticism of Earman is well taken. (See Mayo vs. Earman, however.) But this does not mean the Bayesian cannot learn from Mayo's insight. Instead of talking about the posterior probability of the GTR, the Bayesians can now talk about the posterior probability of "one facet or one hypothesis of" the global theory of GTR; there is no reason why the error theorist can monopolize Mayo's insight. Given a certain measure of "loss" or "gain" (presumably epistemic value) in an experiment, the Bayesian can even reconstruct "accepting a hypothesis" in a similar manner as Neyman-Pearson's procedure, in terms of rational decisions based on such posterior probabilities.
In any case, Mayo's answer to the Alternative Hypothesis Objection is summarized at the end of this chapter.
The MUD charge (for a method of severe testing T) alleges that for any evidence test T takes as passing hypothesis H severely, there is always a substantive rival hypothesis H' that test T would regard as having passed equally severely. We have shown this claim to be false, for each type of candidate rival that might otherwise threaten our ability to say that the evidence genuinely counts in favor of H. Although H' may accord with or fit the evidence as well as H does, the fact that each hypothesis can err in different ways and to different degrees shows up in a difference in the severity of the test that each can be said to have passed. The same evidence effectively rules out H's errors---that is, rules out the circumstances under which it would be an error to affirm H---to a different extent than it rules out the errors to affirming H'. (212)
2nd Assignment, 2001
æµ2ē±ē█æĶ ü@æµ6Å═é╠ŚvÄ|üBāüāCāłü[é═üAmethodological underdetermination é╠¢ŌæĶééŪé╠éµéżé╔ÉžéĶö▓é»éńéĻéķéŲś_éČé─éóéķé╠é®üBŗ’æ╠Śßé╔æ”éĄé─é┼é½éķéŠé»éĒé®éĶéŌéĘéŁüA2000ÄÜł╚ōÓé┼é▄éŲé▀éµüB
Æ„é▀ÉžéĶ6īÄ15ō·üiŗÓüj
Chapter 7. The Experimental Basis from which to Test Hypotheses: Brownian Motion
This chapter deals with specific examples from the 20th century physics, and it is quite instructive. Albert Einstein, in one of his five papers published in 1905, dealt with the so-called Brownian motion, and predicted new observable consequences from the kinetic theory; later a French physicist Jean Perrin conducted a detailed experimental work on the same subject, following Einstein's line. Mayo concentrates on the analysis of Perrin's experiments and his establishment of the kinetic theory on the experimental basis.
See Perrin on Atoms New; Einstein on Brownian Motion Revised; Bull's Eye New; Avogadro's Hypothesis and Avogadro Number New; Herschel's Wrong Calculation New
However, we have to examine carefully Mayo's way of reconstruction: Does Mayo's way in terms of severity work? In other words, we wish to test severely Mayo's claims, not on her criterion of severity but on our criterion! My criticism of Mayo's reconstruction of Perrin is developed (Severity for Perrin?, How does Mayo try to obtain Severity?), and my own reconstruction (which may be acceptable to Mayo, I believe) is finally presented (How to reconstruct Perrin's argument?).
See Severity for Perrin? revised June 19; Argument from Coincidence June 14; How does Mayo try to obtain Severity? revised June 19; Avogadro Number and the Brownian Motion Revised June 19; How to reconstruct Perrin's argument? June 19; How good are Perrin's Measurements? June 19
Notes on Mayo's Severity July 3
3rd Assignment, 2001
æµ3ē±ē█æĶ ü@æµ7Å═ÄÕŚvĢöĢ¬é╠ŚvÄ|üBāüāCāłü[é═üAPerrin é╔éµéķāuāēāEāōē^ō«é╔æ”éĄéĮĢ¬Äqē^ō«ś_é╠ī¤ÅžééŪé╠éµéżé╔Ģ¬É═éĘéķé╠é®üBé┼é½éķéŠé»éĒé®éĶéŌéĘéŁüA2000ÄÜł╚ōÓé┼é▄éŲé▀éµüB
Æ„é▀ÉžéĶ7īÄ3ō·üiē╬üj
Chapter 8. Severe Tests and Novel Evidence
In this chapter, Mayo examines the relationship between the severity of test with the Rule of Novelty (RN). This rule demands: for evidence to warrant a hypothesis H, H should not only agree with the evidence, but the evidence should be novel in some sense. Whether or not this rule is reasonable has been subject to a long-standing dispute among the recent philosophers of science.
Against the defenders of Use-Novelty (data e that was used to arrive at hypothesis H cannot count as a good test of H), such as Worrall or Giere, Mayo argues that what counts is severity, rather than use-novelty. However, when she introduces "a use-constructed test procedure" and tries to illustrate her point, the reader with the Bayesian bent may have a difficulty.
A use-constructed test procedure T: Use e to construct H(e), and let H(e) be the hypothesis T tests. Pass H(e) with e.
This procedure automatically passes H(e) based on e, hence the probability of passing is one. But she introduces a distinction on p. 270 between the following A and B, and argues that the two probabilities are different:
A. The probability that (use-constructed) test T passes the hypothesis it tests
B. The probability that (use-constructed) test T passes the hypothesis it tests, even if it is false.
Since B looks like a conditional probability
P(T passes the hypothesis, the hypothesis is false)
(which, generally, does not make sense on the frequency interpretation), I have asked Mayo for clarification of this distinction, and she kindly answerd (many thanks) with a good example (maybe she should have supplied it right away on p. 270!). évhat she is saying amounts to this: It is one thing that test procedure T passes a hypothesis H(e), given evidence e; it is quite another thing whether this "passing result" is reliable, in her sense of reliability. I take it that, as a frequestist Mayo does not want to use the expression "how H(e) is likely to be true", and that's why she wishes to express the situation in terms of "T passing a hypothesis", or its probability. Passing in A is automatic (hence its probability is 1), but the probability of B is not automatic, and it should be determined by error statistics. In a more direct expression, B means the probability that hypothesis H(e) passes the test T when it is in fact false. To be more specific, consider coin tossing, and you obtain result e which says that the observed relative frequency of head is 2/5; the preceding use-constructed procedure passes the hypothesis "the probability of head is 2/5" automatically on this evidence, and hence the probability of A is 1. However, is the hypothesis thus passed correct? That's quite another question, and the probability of B is concerned with this question, and Mayo's notion of severity is also concerned with this question. Thus, the use-constructed hypothesis may, or may not satisfy severity requirement, depending on the use-constructed test procedure in question, but there is a room that such a procedure can satisfy severity requirement, despite that the probability of A is one.
She tries to use the historical example of the British expedition for confirming one of Einstein's predictions from general relativity, as a good case for severity, but violating use-novelty.
See Diffraction of Light September 11; Eddington on 1919 Expeditions Revised; Eddington on the Deflection of Light September 25
4th Assignment, 2001
æµ4ē±ē█æĶ ü@æµ8Å═ÄÕŚvĢöĢ¬é╠ŚvÄ|üBłĻö╩æŖæ╬ś_é╔éµéķüuÅdŚ═ÅĻé┼é╠ī§é╠Ģ╬ī³üvé╠ī¤ÅžéŚßéŲéĄé─üAÄĶÄØé┐é╠ÅžŗÆé╔éÓéŲé├éóé─ŹņéńéĻéĮē╝ÉÓéāeāXāgéĘéķŹ█é╠¢ŌæĶé╔é┬éóé─üAāüāCāłü[é╠ŗcś_éŚv¢±é╣éµüB2000ÄÜł╚ōÓüAÆ„é▀ÉžéĶ10īÄ2ō·üiē╬üjüB
INDEX- CV- PUBLS.- PICT.ESSAYS- ABSTRACTS- INDEXüELAPLACE- OL.ESSAYS-CRS.MATERIALS
Last modified August 20, 2003. (c) Soshichi Uchii